Funkcja parsująca stronę w poszukiwaniu url’i
Data 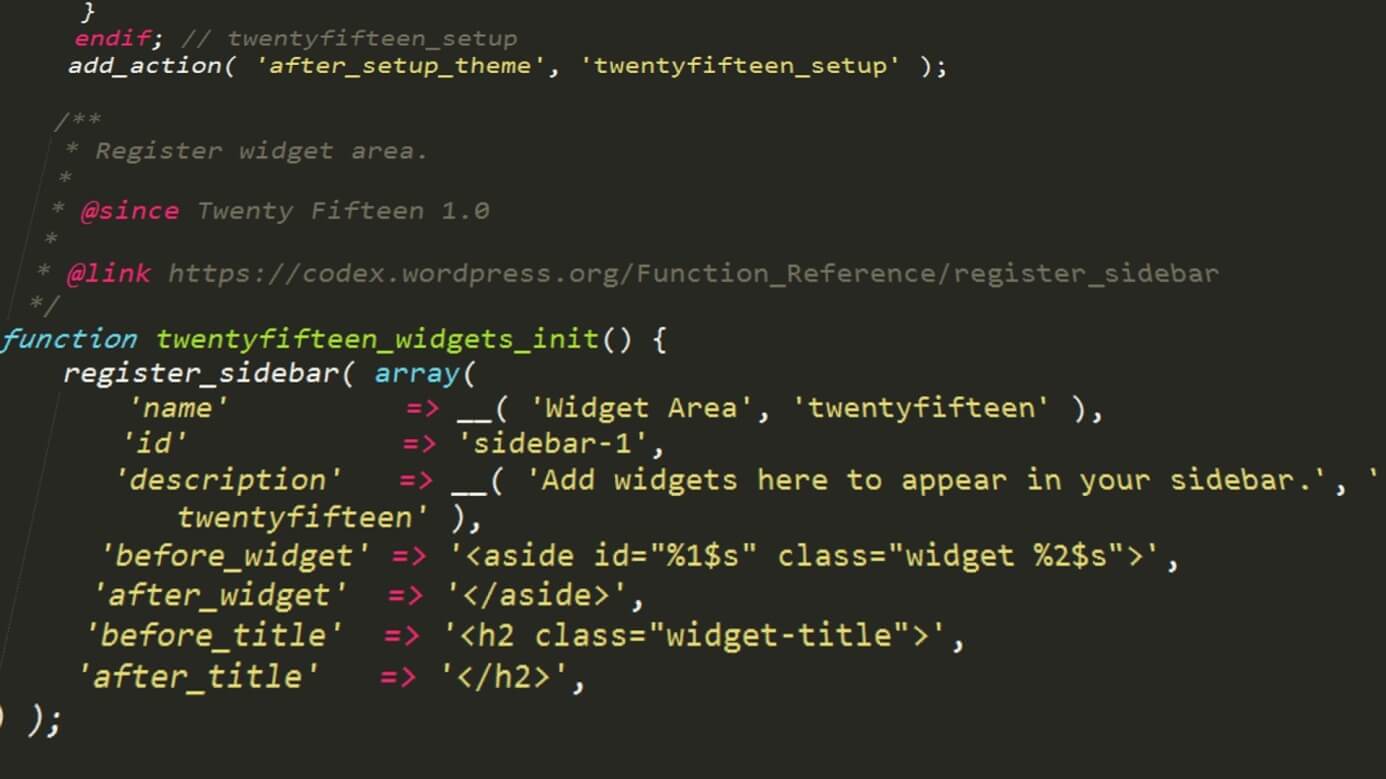
funkcja parsująca
autor Michał Ćwikliński
1 min czytania
Funkcja parsująca stronę w poszukiwaniu url’i
Kolejne wyzwanie i kolejne rozwiązania. Otóż, aby przeparsować stronę w poszukiwaniu wszystkich url’i, które się na niej znajdują, wystarczy użyć rozszerzenia (bliblioteki), która nie jest standardową biblioteką załączaną (włączaną) na serwerach hostingowych. Ale jak ktoś ma szczęście, może skorzystać. Chodzi oczywiście o bibliotekę tidy. Funkcja owa przeparsowuje stronę i wyszukuje znaczniki a, a później ich atrybut href. I “wypluwa” tablicę z naszymi linkami. Proste i piękne….
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
function dump_urls(tidy_node $node, &$urls = NULL) {
$urls = (is_array($urls)) ? $urls : array();
if(isset($node->id)) {
if($node->id == TIDY_TAG_A) {
$urls[] = $node->attribute['href'];
}
}
if($node->hasChildren()) {
foreach($node->child as $child) {
dump_urls($child, $urls);
}
}
return $urls;
}
$tidy = tidy_parse_file("http://www.php.net/");
$urls = dump_urls($tidy->body());
print_r($urls);
Ten post jest udostępniony na licencji CC BY 4.0 przez autora.